TEgO: Teachable Egocentric Objects Dataset

Intro
This dataset includes egocentric images of 19 distinct objects taken by two people for training and testing a teachable object recognizer. Specifically, a blind and a sighted individual takes photos of the objects using a smartphone camera to train and test their own teachable object recognizer.
A detailed description of the dataset (people, objects, environment, and lighting) can be found in our CHI 2019 paper titled “Hands holding clues for object recognition in teachable machines” (see citation below).
Dataset
You can download our full dataset here.
We also provide object heatmap annotations, manually generated by ourselves, for GTEA and GTEA Gaze+. To download the original dataset associated with these object center annotations, please visit the GTEA website and download their hand masks data.
Collection Process
- Training: an individual takes around 30 consecutive photos of each object to train a teachable object recognizer.
- Testing: an individual takes one photo at a time (a total of 5) for each object to test the recognition accuracy of their model. An object is randomly assigned each time.
Annotation Process
Images are manually annotated with hand masks, object center heatmaps, and object labels.

Structure
Note that only the training set includes hand masks and object center annotation data. In each environment folder, there are several folders, each of which contains images taken under a different condition.
- Training:
- Images (original images)
- vanilla (in a plain environment)
- wild (in a cluttered environment)
- Masks (hand mask images)
- vanilla
- wild
- Objects (object center annotation images)
- vanilla
- wild
- Images (original images)
- Testing
- Images (original images)
- vanilla (in a plain environment)
- wild (in a cluttered environment)
- Images (original images)
- README.txt (readme text)
- labels_for_training.json (object-label mapping for the training data)
- labels_for_testing.json (object-label mapping for the testing data)
JSON data structure
Two json files (labels_for_training.json and labels_for_testing.json) share the same structure. Below is the structure of the JSON data.
{
(environment):
{
(method):
{
(image filename): (label),
...
},
...
},
...
}
Further detail
- environment can be either “vanilla” or “ wild”
- an example of a method can be “B1_PS_H_train” or “B1_PV_NH_test_torch”
Metadata
- B1: data from a blind individual
- S1: data from a sighted individual
- PS: images taken using the screen button in the portrait mode (P: portrait mode, S: screen button)
- PV: images taken using the volume button in the portrait mode (P: portrait mode, V: volume button)
- H: images with the subject’s hand
- NH: images without the subject’s hand
- train: images taken for training
- test: images taken for testing
Metadata for the testing data
- (No additional mark): images taken under the same environment as the training’s
- NIL: images taken under the no-indoor-lighting environment
- torch: images taken using torch/flashlight of a phone
Example
In the B1_PS_H_train folder, for example, the images, which include the subject’s hand, were collected by the blind subject using the screen button in the portrait mode to train a teachable object recognizer. In the B1_PS_H_test_NIL, for example, the images, which include the subject’s hand, were taken when indoor lights were turned off to test a teachable object recognizer.
Citation
Please cite our corresponding paper if you find our dataset useful. Following is the BibTex of our paper:
@inproceedings{lee2019hands,
title={Hands Holding Clues for Object Recognition in Teachable Machines},
author={Lee, Kyungjun and Kacorri, Hernisa},
booktitle={Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems},
year={2019},
organization={ACM}
}
License
This dataset is licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) License.
Funding
The work was supported, in part, by grant number 90REGE0008 (Inclusive ICT Rehabilitation Engineering Research Center), from the National Institute on Disability, Independent Living, and Rehabilitation Research (NIDILRR), U.S. Administration for Community Living, Department of Health and Human Services.
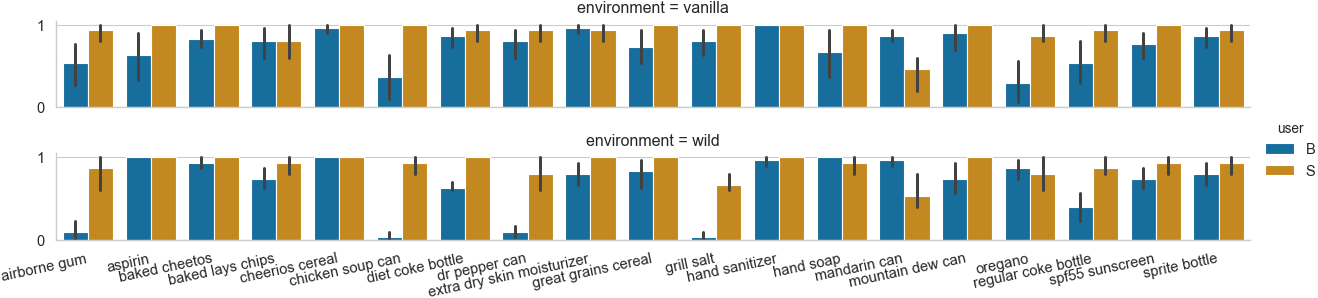
Our results on TEgO
Following is the performance of our hand-guided object recognition system on TEgO. It shows the average recall per object in two different environments (vanilla and wild). The results were generated with our hand-guided object recognizer that was trained with images cropped by our object localization model.
Contact
If you have any questions, please contact Kyungjun at kjlee@cs.umd.edu.